
Пошук власника сайту. Websites OSINT
Привіт друже. Займаючись OSINT на практиці, ти рано чи пізно зіткнешся із завданням, коли тобі потрібно буде знайти того, кому належить якийсь сайт. Навіщо тобі це знадобиться це питання другорядне, та залежить від ситуації. А ось як це зробити, може бути проблемою. Ну чи, як мінімум, досить трудомістким завданням. Я вже писав статті щодо вивчення сайтів. У них я розібрав, як шукати метадані на сайтах і як шукати каталоги та файли. І, хоч, це не зовсім деанон власника, але застосовувати ці способи теж варто, бо є шанс отримати інформацію, що веде до власника.

Сам процес пошуку власника сайту може виявитися досить замороченою історією. Сенс у тому, що неможливо спрогнозувати які дані дадуть результат. З цієї причини, не може існувати якогось єдиного алгоритму дій, що гарантує успіх. Тому ця стаття буде у форматі чек-листа. Тобто. у вигляді набору дій, які, як окремо так і в комплексі, можуть призвести до потрібного результату.
Вивчаємо сайт та його контент
У більшості випадків, перше, що потрібно зробити, як би банально це не прозвучало, це вивчити вміст сайту і виписати все, що може представляти інтерес. Насамперед варто звертати увагу на контактні дані, такі як телефони, пошти, адреси чи посилання на соціальні мережі. Якщо на сайті є Політика конфіденційності, її варто обов’язково переглянути тому що там також можуть бути контакти, або згадується назва організації, якій належить сайт.
Форма зворотнього зв’язку
Також варто звернути увагу на наявність форм зворотнього зв’язку або можливість підписатись на розсилку. Якщо розсилка є, на неї можна підписатись і подивитися з якої пошти прийде лист. Цю адресу електронної пошти можна додатково вивчити. А іноді в таких розсилках, лист підписується ім’ям справжньої людини або містить додаткову контактну інформацію.
Форма зворотного зв’язку також може знадобитися, якщо ти зайдеш у глухий кут. Тоді можна увімкнути соціального інженера та спробувати туди написати щось таке, що спонукає тобі відповісти. Це може дати тобі додаткові контакти, вивчивши які, можливо, вдасться знайти власника сайту.
Фотографії
Якщо на сайті є якісь фотографії або картинки, їх обов’язково варто пошукати через пошукові системи. Насамперед це допоможе зрозуміти наскільки вони унікальні. Якщо це згенеровані зображення, стокові або просто знайдені через пошук, це звичайно навряд чи нам щось дасть. Але вони можуть виявитися досить унікальними. І, наприклад, привести нас до соціальних мереж власника сайту, або до його облікових записів на інших ресурсах, де він їх публікував. Також у цій ситуації можна пробувати працювати з тим, що зображено на фотографіях. Пробувати геолокувати місце або ідентифікувати людей та об’єкти на фотографіях.
Тексти та автори
Також варто звертати увагу на тексти, які розміщені на сайті. Наприклад статті чи описи чогось. Можна пошукати їх у Google, використовуючи лапки, щоб знайти точний збіг і дізнатися на яких сайтах ці тексти ще зустрічаються.
Якщо в публікаціях на сайті, наприклад, у статтях, вказані автори, то їх теж варто вивчити на предмет того, яке відношення вони мають до цього сайту. Цілком можливо, що один з авторів це власник. Або, наприклад, ще один можливий варіант. Якщо авторів багато, можна знайти їхні соціальні мережі та переглянути перетини та збіги за контактами. Серед яких цілком може бути власник сайту.
Платежі
Якщо на сайті є можливість щось сплатити чи закинути донат, туди варто натиснути. Найчастіше нас перекине на якусь платіжну систему. І це означає що при оформленні платежу, ми побачимо або повні дані, або частину даних того у чию користь відбувається платеж.
Загалом, суть у тому, що, перед тим як ти почнеш використовувати якісь сервіси або софт, потрібно банально ручками поклацати по сайту і подивитися, що там є. Цілком може статися, що ти знайдеш все, що тобі потрібно, або, як мінімум, отримаєш якісь вихідні дані, з якими можна буде працювати далі.
Пошукові системи
Наступним кроком варто подивитися, що про сайт знають пошукові системи. Для цього використовуємо дорки для пошуку по повному співпадінню. Якщо результатів дуже багато, фільтрувати потрібні допоможе дорк: site:. Щоб прибрати посилання з нашого сайту, що вивчається, використовуємо: -site:.
"hacker-basement.com" -site:hacker-basement.com
Якщо сайт часто згадується десь, де нам не цікаво, цим же дорком виключаємо не потрібні нам ресурси. Або, навпаки, шукаємо на якихось конкретних сайтах. Взагалі, пошук по точному співпадінню, дуже добре працює для пошуку згадок потрібної нам сторінки. Тому застосовувати його варто не тільки для головної сторінки, але і для інших сторінок сайту, які нас зацікавили. Тому що цілком може статися, що хтось писав пост, в якому розмістив посилання, або в якійсь статті вона згадувалась ну і т.п. Варіантів багато, а нам буде корисна будь-яка додаткова інформація. До речі, посилання можна пробувати шукати у пошуку соціальних мереж. Є вірогідність знайти пости в яких це посилання згадувалося.
Реєстраційні дані. Кому належить сайт?
Перегляд даних WHOIS — це історія з розділу «а раптом пощастить». На практиці, знайти там дані власника, шансів практично немає, тому що із завданням натиснути кнопку «Privacy Protection», при реєстрації домену, справляються майже всі. Найкорисніша інформація, яку можна звідти отримати і яка може іноді стати в нагоді, це дізнатися хостинг і країну. Але і це спрацює лише якщо власник сайту не особливо шифрується. Тому що існує купа анонімних хостингів, з якихось офшорних територій, що ще й приймають оплату криптою. Список подібних хостингів викладав у Telegram: https://t.me/Pulsechanel/425.
Проте процес ознайомлення із записами WHOIS займає не дуже багато часу, тому нехтувати ним не варто. Тому йдемо на https://www.whoxy.com і вводимо в поле пошук сайт, який нас цікавить.

Історія змін WHOIS
Крім ознайомлення з поточними реєстраційними даними, є сенс заглянути в історію зміни цих записів. Вона доступна на цьому ж сайті:
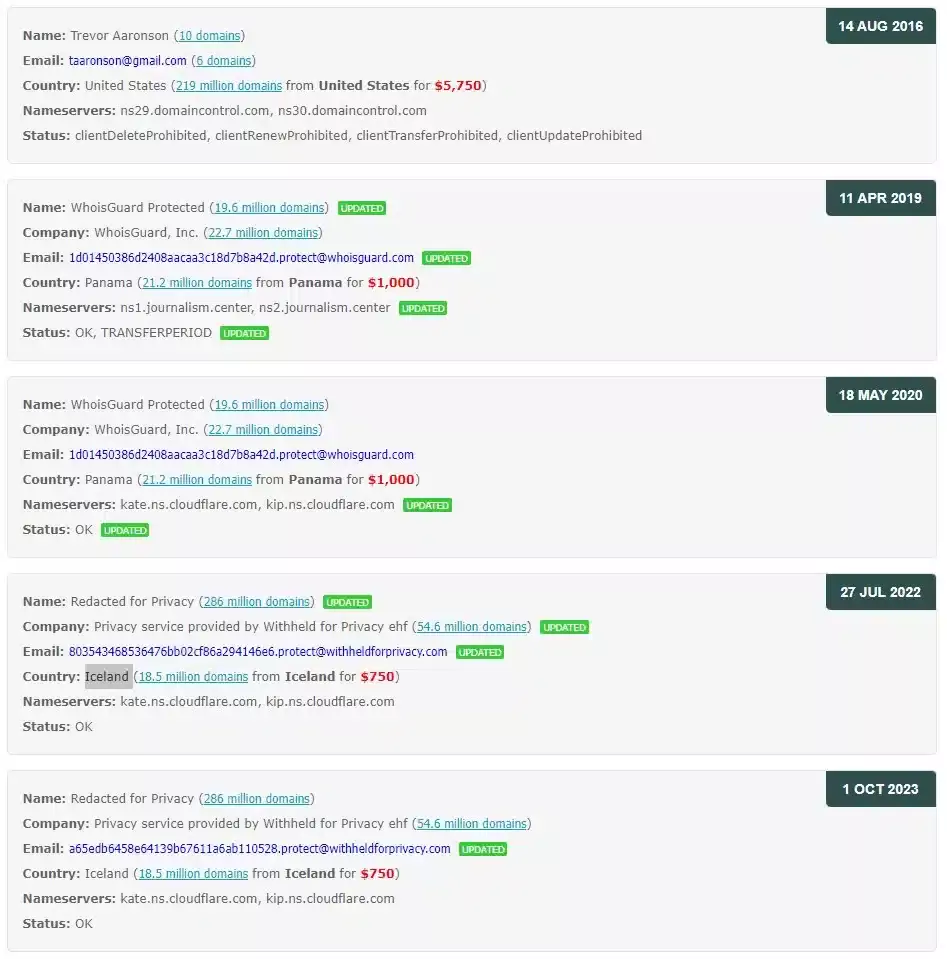
З прикладу на скрині вище, ми бачимо, що включений Privacy Protection, відповідно даних власника ми не дізнаємося. Сам сайт знаходиться в Ісландії, та й CloudFlare теж присутній. З історії записів ми, до Ісландії, бачимо Панаму. Але за найпершим записом, від 2016 року, ми можемо побачити, що домен реєструвався на конкретну людину. У тому числі ми бачимо його пошту та інші домени зареєстровані на нього та на його пошту. А також те, що перша реєстрація була в Америці.
Саме собою це, звичайно ж, ще не означає, що цей домен досі належить цій людині. Хоча це також не виключено. Але варто пам’ятати, що він міг цей домен, наприклад, продати. Незважаючи на це, з історії записів, ми отримали цілком конкретний напрямок, який можна буде опрацювати.
На цьому ж ресурсі ми можемо зробити зворотний пошук доменів по імені, назві компанії, електронній пошті та за ключовими словами. Це може бути корисно, якщо потрібно знайти належні комусь домени.
Ще один ресурс для зворотного пошуку: https://whoisology.com. Вміє шукати за доменом, електронною поштою та ключовими словами.
Веб-архів
При вивченні якогось сайту, особливо якщо це велике розслідування, крім того, що потрібно зберігати собі знайдену інформацію, є сенс також зберігати сторінки сайту, на яких ця інформація була знайдена. Це потрібно, щоб можна було пізніше повернутися до цієї сторінки та повторно вивчити. А також якщо сайт буде видалено або змінено, у тебе залишаться пруфи, що інформація була знайдена саме там. Яким чином це робити не дуже важливо, роби так як зручніше тобі. Я, наприклад, зберігаю сторінки у PDF. Хтось додає їх до веб-архіву. Комусь більше подобається викачувати весь сайт. А хтось просто робить скріншоти.
Робота з веб-архівом
Також важливо пам’ятати, що інформація на сайті, з часом, могла бути видалена або змінена. І буває так, що це саме та інформація, яка нам потрібна. У цій ситуації нам допоможе веб-архів.
https://archive.org — вводимо адресу потрібного нам сайту і бачимо календар, в якому відмічені дати, за які є збережені знімки. Зверху бачимо часову шкалу із розбивкою за роками. Тут важливо пам’ятати, що це не дати, коли на сайт вносилися зміни. Archive.org не стежить за сайтами в режимі он-лайн. Це дати, коли сайт сканувався і робився його знімок.

Пошук змін
Якщо потрібно дізнатися, коли і які зміни вносилися, то переходимо в розділ «Changes». Тут синіми та зеленими квадратиками позначені дати коли зроблений знімок відрізнявся від попереднього. Ми можемо вибрати потрібні нам дати та натиснути «Compare». Після цього відкриється вікно, розділене на дві частини. Вони будуть показувати знімки нашого сайту за вибрані дати. Виявлені зміни в одному вікні будуть відмічені жовтим, в іншому синім. У такий спосіб можна швидко знаходити що було змінено на сайті.
У цьому прикладі ми дивилися знімки головної сторінки сайту, але в реальній ситуації нам майже завжди потрібно буде ознайомитися і з іншими сторінками. Можна звичайно просто копіювати посилання та шукати по ньому. Це зручно, якщо ми точно розуміємо яка саме сторінка нам потрібна. А якщо ми цього не знаємо, то у нас є вкладки «Site Map» та «URLs».
На вкладці Site Map ми побачимо карту сайту у вигляді діаграми. У центрі буде головна сторінка, а довкола будуть сторінки, знімки яких є в архіві. Коли ми наводимо курсор на елемент, нам показують посилання на відповідну сторінку. Також ми можемо вибрати, за який рік нас цікавить інформація.
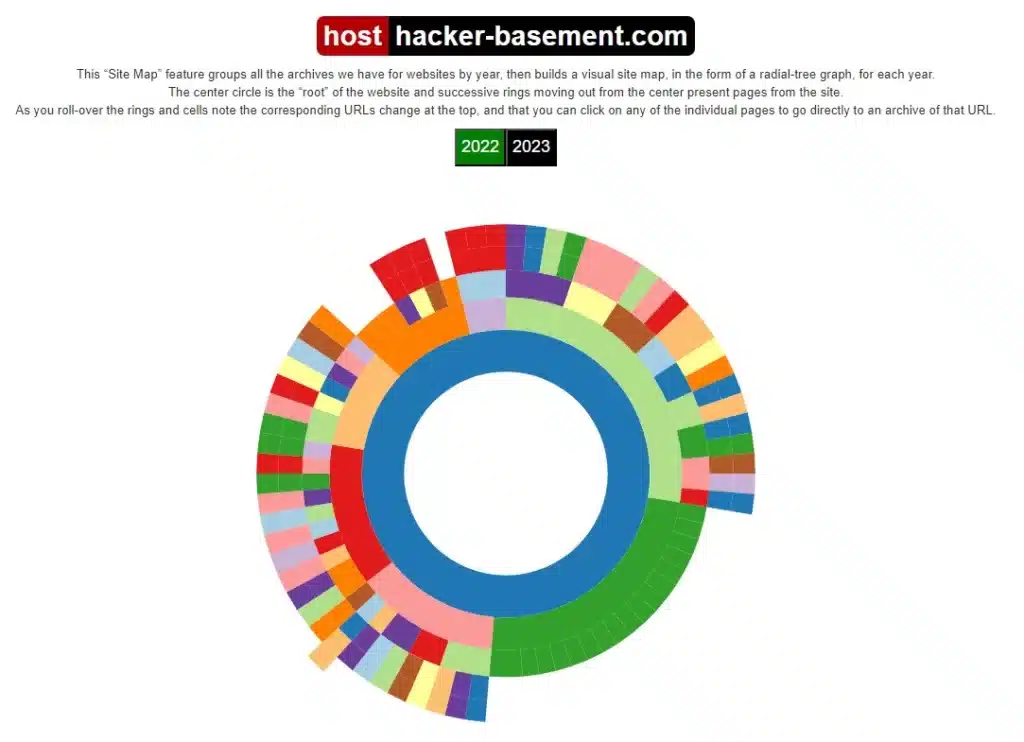
На вкладці «URLs» ми побачимо список сторінок сайту, для яких є знімок. У тому числі бачимо скільки всього було знімків, скільки з них унікальних, а скільки однакових.
https://archive.is – ще один веб-архів. Простіше ніж попередній, без будь-яких заморочених функцій. Просто зберігає знімки сторінок та робить скріншот сторінки. Працює досить швидко. І, на мою думку, він зручний саме як інструмент збереження потрібних сторінок, а не інструмент вивчення сайту.
Кеш сайту
Також не варто забувати про таку штуку як кеш гугла. Сенс його в тому, що бот гугла, коли відвідує сторінку, зберігає її в кеші в тому вигляді, в якому вона була на момент відвідування. Це може бути корисно, коли потрібний нам сайт не доступний на даний момент.
Є кілька способів переглянути дані з кешу. Можна прямо з пошукової системи. Знаходимо необхідну нам сторінку. Біля адреси тиснемо на три крапки і, у вікні, що відкриється, натискаємо «Збережена копія».

Ще один спосіб це сходити на http://www.cachedpages.com. І там вставити потрібне посилання, там же можна перейти до веб-архіву.
Моніторинг змін
Наступна ситуація може статися, якщо ти вивчаєш чиюсь діяльність. Тобі може знадобитися моніторити зміни сайту в реальному часі.
https://distill.io — це розширення браузера, також можна встановити десктопну програму. На мій погляд, це оптимальний варіант. У безкоштовній версії можна відстежувати 25 посилань. Можна налаштувати, щоб він звертав увагу лише на якісь конкретні зміни. Також він веде журнал змін, тобто. запам’ятовує коли та які зміни вносилися на сторінку, що також дуже важливо.
https://www.followthatpage.com — те саме, але в трохи більш спрощеному варіанті. Додаємо посилання на потрібну нам сторінку, після чого вказуємо нашу електронну пошту. Після додавання можна буде настроїти фільтри. Фільтрувати можна за рядками або блоками. Якщо фільтруємо по рядках, потрібно вказати ключове слово і всі рядки, що містять це слово, будуть ігноруватися. Якщо фільтруємо по блоках, потрібно вибрати початок і кінець блоку, все що між ними буде ігноруватися. Повідомлення про зміни будуть надходити на вказану пошту, в листі буде вказано що саме змінилося на сторінці, що відстежується. Безкоштовна версія може стежити за 20 сторінками.
Якщо потрібно стежити за великою кількістю ресурсів, то є платний варіант: https://changedetection.io. Зручно, ціла купа будь-яких можливостей та налаштувань, але за гроші. Є ще варіант, у попередніх сервісах створити купу облікових записів і стежити за великою кількістю сайтів, але це, скажімо так, буде не найкомфортніша історія.
Рекламні ідентифікатори
Багато сайтів використовують у себе сервіси Google для аналітики та монетизації. Ці сервіси кожному обліковому запису надають унікальний ідентифікатор, який потім використовується на всіх сайтах, що мають відношення до цього облікового запису. Відповідно, ми можемо, використовуючи ці ідентифікатори, знаходить афілійовані сайти. Але при цьому слід розуміти деякі нюанси.
Google Analytics – це сервіс для статистики та відстеження активності користувача на сайті. Там ще купа всього, але зараз це не дуже важливо. Важливо розуміти, що обліковий запис просто прив’язаний до пошти, а значить їх можна створити нескінченно багато. Ну і якоїсь персональної прив’язки до людини, крім адреси пошти, він мати не буде.
AdSense – це сервіс для монетизації. Реклама, яку ти бачиш на сайті, додається через AdSense. І оскільки це баблова історія, то й процедура реєстрації складніша і є обмеження: один акаунт на одну особу. Але найголовніша проблема там, це фізичний лист, який приходить на поштову адресу і йти він може близько місяця, а то й більше. У цьому листі буде код, і доки ти його не введеш, бабло ти отримувати не будеш.
Зрозуміло, що це теж не панацея і, при бажанні, можна зареєструвати декілька акаунтів на дропів. Але заморочена процедура реєстрації збільшує ймовірність того, що на декількох сайтах буде один і той самий AdSense. Відповідно, при вивченні сайту, у пріоритеті варто звертати увагу саме на ідентифікатор AdSense.
Ідентифікатор Google Analytics має формат: UA-набір цифр.
Ідентифікатор AdSense має формат: ca-pub-набір цифр або pub-набір цифр.
Пошук ідентифікаторів
Є кілька способів, як їх знаходити. Можна вручну. Відкриваємо потрібну сторінку, тиснемо Ctrl+U. Відкриється вкладка перегляду коду сторінки. Тут тиснемо Ctrl+F, і в пошуку пишемо UA- або pub-

Якщо руками шукати не хочеться, то можна використовувати сервіси які вміють їх витягувати. Там же можемо відразу пошукати сайти, на яких використовуються такі ж ідентифікатори. Найоптимальніший варіант це https://analyzeid.com. Просто вводимо потрібну нам адресу сайту, і він сам знайде ідентифікатори та всі сайти, які їх використовують.
Шукає він дуже добре, але щоб перестрахуватися можна перевірити і на інших подібних ресурсах:
https://dnslytics.com — у розділі Reverse Tools вибираємо Reverse Adsense або Reverse Analytics та шукаємо по потрібному нам ідентифікатору.
https://spyonweb.com – у полі пошуку вводимо домен або ідентифікатор, дивимося результати. Теж справляється дуже гідно.
Метадані
Тема з метаданими стара як світ, але, незважаючи на це, цілком може давати результати. Якщо говорити про метадані медіафайлів, то перевірити, хоча б вибірково, звичайно можна, але шанси отримати результат відверто не великі. Тут потрібно дивитися за ситуацією, якщо ми бачимо якісь стокові картинки або зображення явно взяті з пошуку, то можна й не морочитися. Тим більше, що популярні CMS, той же WordPress наприклад, вміють чистити метадані медіафайлів, що завантажуються. Тому, у випадку з картинками, якщо вони хоч трохи унікальні, набагато актуальніше через пошук за зображеннями пошукати де вони ще зустрічаються.
Перевірити метадані зображення можна тут: https://www.imgonline.com.ua/exif.php
Набагато більш актуальною є тема метаданих у документах. Їх набагато рідше чистять примусово. Інше питання в тому, що документи далеко не на всіх сайтах присутні, але варто перевіряти завжди. Та якщо вони все-таки є, то, крім метаданих, потрібно обов’язково дивитися вміст, там цілком можуть бути якісь потрібні дані.
Шукати документи на сайті можна за допомогою Google та його дорків filetype: і site:, наприклад:
filetype:pdf site:hacker-basement.com
Якщо документів більше ніж трохи, то руками качати і перевіряти це не найоптимальніший варіант. Особливо з огляду на те, що крім pdf, нам потрібно ще перевірити текстові документи, таблиці та презентації. У такій ситуації варто використовувати утиліту Metagoofil. Вона скачає всі необхідні нам файли, витягне метадані і покаже їх у зручному вигляді. Детальну інструкцію по Metagoofil я вже писав, тому повторювати не бачу сенсу: Метадані. Metagoofil. Що та як можна знайти на сайті?
Сайт та технології
Вивчення технологій сайту, або, іншими словами, того що у нього під капотом, з точки зору OSINT, це історія з серії «я тебе по IP вирахую». Тобто. шанс, звичайно, є, але дуже не великий. Я саме тому цей розділ помістив у кінець статті. Але, заради справедливості, варто відзначити, що іноді, все-таки з цього всього можна отримати корисну інформацію, яка, в комплексі з іншими даними, може дати результат. Тож давай розберемося з деякими моментами.
VirusTotal
Взагалі, перше, що тобі потрібно зробити, перед вивченням сайту, ще до того, як ти на нього зайдеш, це перевірити його на https://www.virustotal.com. По-перше переконатись, що з сайтом все добре і ти не зачепиш звідти щось не хороше. По-друге отримати первинну інформацію.
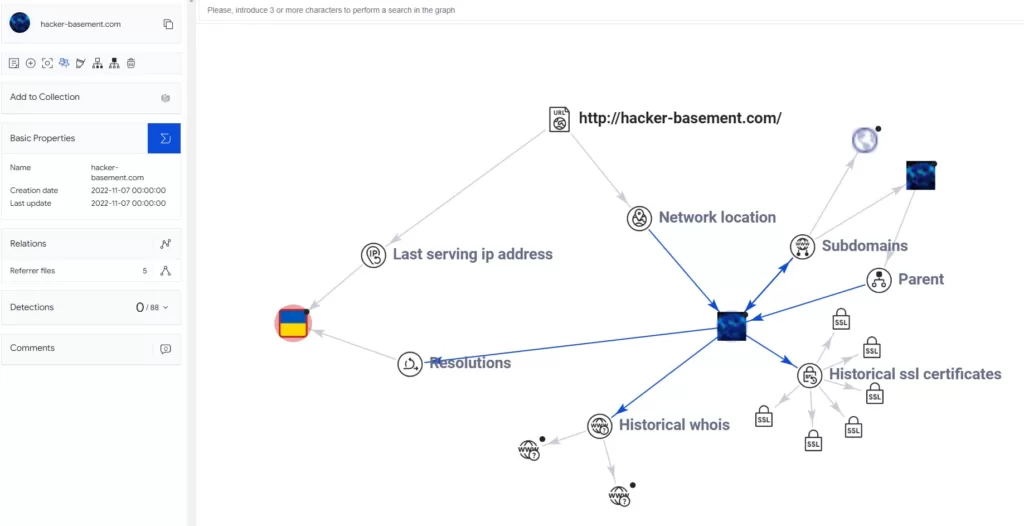
У розділі DETAILS ми можемо подивитися IP сайту (і звідти його перевірити), а також побачити заголовки, опис та трекери які на сайті використовуються, в тому числі їх ідентифікатори. У розділі LINKS ми побачимо всі вихідні посилання на сторінці. Також корисним може бути розділ Graph. Тут можна в графічному вигляді створити схему зв’язків сайту, його IP, піддоменів і т.п., у тому числі можна переглянути історію WHOIS та SSL сертифікатів.
SSL сертифікати
Ну і якщо я згадав SSL сертифікати, то давай кілька слів про це. Це така штука яка потрібна щоб шифрувати дані під час передачі тобто використовувати протокол HTTPS, це елемент підвищення довіри між клієнтом та сервером. Цей сертифікат видається центрами сертифікації. Дуже часто ти бачитимеш сертифікат виданий Let’s Encrypt. Тому що це безкоштовно та будь-який адекватний хостинг вміє підключати цей сертифікат на автоматі. Для його отримання не потрібна будь-яка персональна інформація. Отже для нас він марний.
Але іноді, переважно великі організації, купують платний сертифікат. І в цьому випадку ми можемо отримати корисну інформацію. Там буде вказано назву організації, яка купила сертифікат та електронну пошту. А, аналізуючи історію цих сертифікатів, можна збирати дані про організації, які мають відношення до сайту, що вивчається.
https://crt.sh — вводимо потрібний нам домен і дивимося інформацію про SSL сертифікати.
Технології
Повернемося до технологій. Є величезна кількість ресурсів, які дозволяють отримати дані про сайт, але особисто мені подобається і більш зручний https://web-check.as93.net
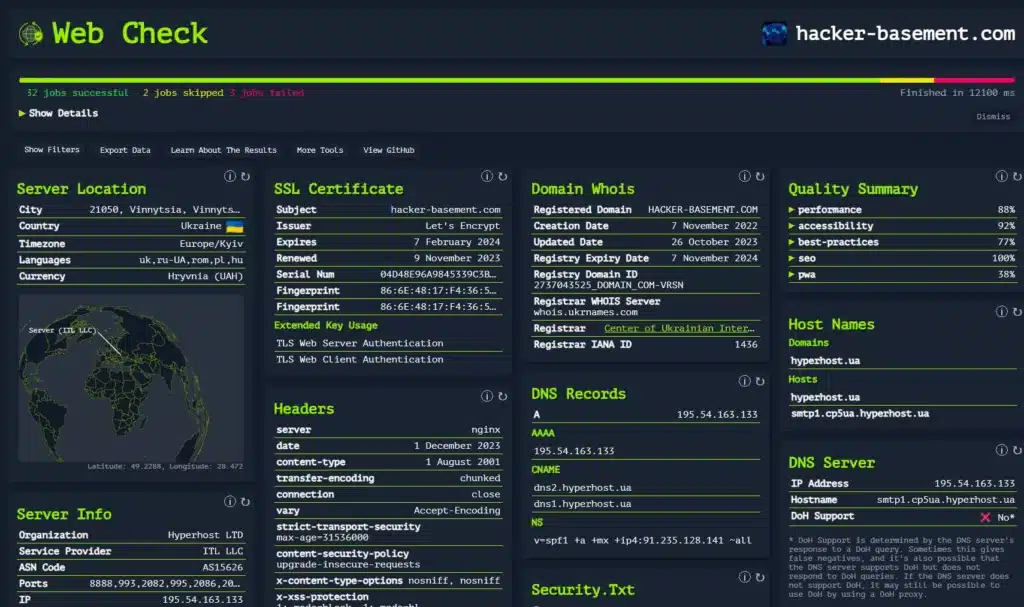
Інформації там буде багато, але далеко не вся вона може бути нам корисною. Давай подивимося, що ми можемо використовувати.
Локація сервера. Тобто. в якій країні хоститься сайт, іноді буде інформація про місто. Це, звичайно, далеко не завжди означає, що власник сайту теж знаходиться там. Найчастіше це локація хостингу. Але все ж таки деяку прив’язку до місцевості це дає, тому звертаємо увагу. Тут ще варто подивитися на записи NS в розділі DNS Records. Якщо ти бачиш Cloudflare, то локацію тобі покаже із США. Але це локація Cloudflare, не сервер сайту.
DNS запис. Тут ми бачимо IP адресу і можемо відразу сходити на https://dnslytics.com і через зворотний пошук подивитися інші сайти на цьому IP. Хоча тут також є нюанси. По-перше, звертаємо увагу на розділ Host Names. Якщо там бачимо якийсь хостинг, то це місія немає ніякого сенсу, тому що сайтів на цій адресі, буде ціла купа і знайти пов’язані, навіть якщо вони там є, по одному тільки IP не вийде. Ця маніпуляція буде мати сенс, якщо на одній IP адресі знаходиться якась невелика кількість сайтів.
У розділі Pages ми побачимо sitemap сайту. З корисного звідти ми можемо дізнатися про хронологію зміни сторінок і додавання картинок. Не факт що це дуже корисна інформація, але в комплексі з якимись ще даними може знадобитися.
У розділі Linked Pages ми можемо побачити внутрішні та зовнішні посилання на сторінці.
Ще варто звернути увагу на розділ Redirect Chain. Якщо сайт хоче нас кудись перенаправити, можливо, це якісь пов’язані між собою ресурси.
Підсумок
Як бачиш процес пошуку власника сайту може виявитися досить замороченим завданням. Але при цьому не неможливим. Основні напрямки, куди дивитись я тобі показав. А від тебе потрібна лише уважність і трохи аналітичного мислення, у плані комбінування інформації між собою та пошуку правильних напрямків. Тобто. коли ти знайшов якусь зачіпку, її потрібно правильно використати і доповнити, перетворивши на ланцюжок, що веде до результату. Також дуже важливо виписувати всю знайдену інформацію. Не намагайся тримати її в голові, ти в будь якому разі щось пропустиш або забудеш.
Твій Pulse.