
Поиск владельца сайта. Websites OSINT
Привет, друг. Занимаясь OSINT на практике, ты, рано или поздно, столкнёшься с задачей, когда тебе нужно будет найти того, кому принадлежит какой-то сайт. Зачем тебе это понадобится это вопрос второстепенный, зависящий от ситуации. А вот как это сделать, может быть проблемой. Ну или, как минимум, довольно трудоёмкой задачей. Я уже писал статьи на тему изучения сайтов. В них я разобрал как искать метаданные на сайтах и как искать каталоги и файлы. И, хоть, это не совсем деанон владельца, но применять эти способы тоже стоит, потому как есть шанс получить информацию ведущую к владельцу.

Сам по себе процесс поиска владельца сайта может оказаться достаточно замороченной историей. Смысл в том, что невозможно спрогнозировать какие данные дадут результат. По этой же причине, не может существовать какого-то единого алгоритма действий, гарантирующего успех. Поэтому эта статья будет в формате чек-листа. Т.е. в виде набора действий, которые, как по отдельности так и в комплексе, могут привести к нужному результату.
Изучаем сайт и его контент
В большинстве случаев, первое что нужно сделать, как бы банально это не прозвучало, это изучить содержимое сайта и выписать всё что может представлять интерес. В первую очередь стоит обращать внимание на контактные данные, такие как телефоны, почты, адреса или ссылки на социальные сети. Если на сайте есть «Политика конфиденциальности», её стоит обязательно просмотреть т.к. там тоже попадаются контакты, либо упоминается название организации, которой принадлежит сайт.
Форма обратной связи
Также стоит обратить внимание на наличие форм обратной связи или возможность подписаться на рассылку. Если рассылка есть, на неё можно подписаться и посмотреть с какой почты придёт письмо. Этот адрес электронной почты дополнительно можно будет изучить. А иногда в таких рассылках письмо подписывается именем настоящего человека, либо содержит дополнительную контактную информацию.
Форма обратной связи также может понадобится если ты зайдёшь в тупик. Тогда можно включить социального инженера и попробовать туда написать что-то такое, что побудит тебе ответить. Это может дать тебе дополнительные контакты, изучив которые, возможно, получится найти владельца сайта.
Фотографии
Если на сайте есть какие-то фотографии или картинки, то их обязательно стоит поискать через поисковики. В первую очередь это поможет понять на сколько они уникальны. Если это сгенерированные изображения, стоковые или просто найденные через поиск, то это конечно вряд ли нам что-то даст. Но если вдруг фотографии окажутся достаточно уникальными, то, могут например, привести нас к социальным сетям владельца сайта, или к его аккаунтам на других ресурсах, где он их публиковал. Также в этой ситуации можно пробовать работать с тем что изображено на фотографиях. Пытаться геолоцировать место или идентифицировать людей и объекты на фотографиях.
Тексты и авторы
Также стоит обращать внимание на тексты которые размещены на сайте. Например статьи или описания чего-нибудь. Можно поискать их в Google, используя кавычки, чтобы найти точное совпадение и узнать на каких сайтах ещё эти тексты встречаются.
Если в публикациях на сайте, например в статьях, указаны авторы, то их тоже стоит изучить на предмет того какое отношение они имеют к этому сайту. Вполне может быть что один из авторов это владелец. Или, например, ещё одни возможный вариант. Если авторов много, можно найти их социальные сети и посмотреть пересечения и совпадения по контактам. Среди которых вполне может оказаться владелец сайта.
Платежи
Если на сайте есть возможность что-то оплатить или закинуть донат, то туда стоит нажать. В большинстве случаев нас перекинет на какую-нибудь платёжную систему. А это означает что при оформлении платежа мы увидим либо полные данные, либо часть данных того в чью пользу совершается платёж.
В общем, смысл в том, что, перед тем как ты начнёшь использовать какие-то сервисы либо софт, нужно банально ручками поклацать по сайту и посмотреть что там есть. Вполне может случиться, что ты найдёшь всё что тебе нужно, либо, как минимум, получишь какие-то исходные данные, с которыми можно будет работать дальше.
Поисковые системы
Следующим шагом стоит посмотреть, что о сайте знают поисковые системы. Для этого используем дорки для поиска по полному совпадению. Если результатов очень много, отфильтровать нужные поможет дорк: site:. Что бы убрать ссылки с нашего изучаемого сайта используем: -site:.
"hacker-basement.com" -site:hacker-basement.com
Если сайт часто упоминается где-то, где нам не интересно, этим же дорком исключаем не нужные нам ресурсы. Либо, наоборот, ищем на каких-то конкретных сайтах. Вообще, поиск по точному совпадению, очень хорошо работает для поиска упоминаний интересующей нас страницы. Потому применять его стоит не только для главной страницы, но и для других страниц сайта, которые нас заинтересовали. Потому что вполне может случиться, что кто-то писал пост, в котором разместил ссылку, либо в какой-то статье она упоминалась, ну и т.д. Вариантов много, а нам будет полезна любая дополнительная информация. Кстати, ссылки можно пробовать искать в поиске в социальных сетях. Есть вероятность найти посты в которых эта ссылка упоминалась.
Регистрационные данные. Кому принадлежит сайт?
Просмотр данных WHOIS это история из раздела «а вдруг повезёт». На практике, найти там данные владельца, шансов практически нет, потому как с задачей нажать кнопку «Privacy Protection», при регистрации домена, справляются почти все. Самая полезная информация которую можно оттуда получить и которая может иногда пригодится, это узнать хостинг и страну. Но и это сработает только если владелец сайта не особо шифруется. Потому как существует куча анонимных хостингов, из каких-нибудь офшорных территорий, ещё и принимающих оплату криптой. Список подобных хостингов давал в Telegram: https://t.me/Pulsechanel/425.
Тем не менее процесс ознакомления с записями WHOIS занимает не особо много времени, потому пренебрегать им не стоит. Поэтому идём на https://www.whoxy.com и вводим в поле поиск интересующий нас сайт.

Кроме ознакомления с текущими регистрационными данными, есть смысл заглянуть в историю изменения этих записей. Она доступна на этом же сайте:
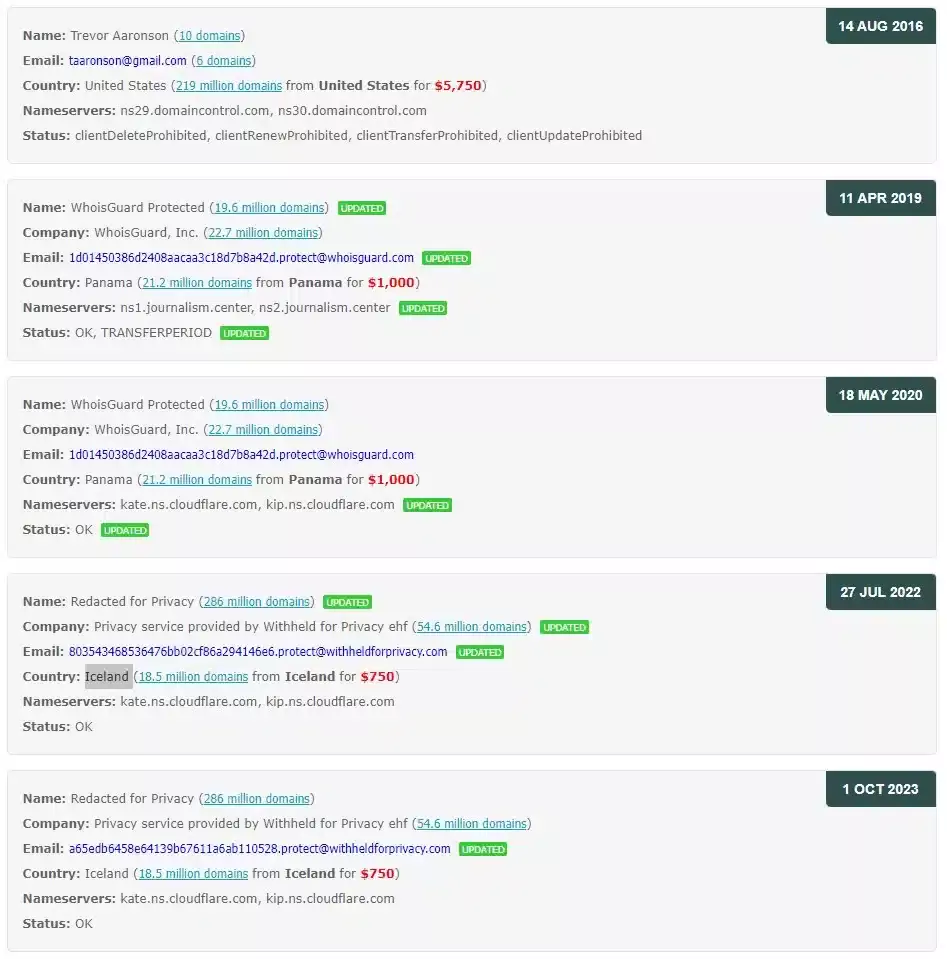
Из примера на скрине выше, мы видим что включен Privacy Protection, соответственно данных владельца мы не узнаем. Сам сайт находится в Исландии, ну и CloudFlare тоже присутствует. По истории записей мы, до Исландии, видим Панаму. Но по самой первой записи, от 2016 года, мы можем увидеть что домен регистрировался на конкретного человека. В том числе мы видим его почту и другие домены зарегистрированные на него и на его почту. А также то что первая регистрация была в Америке.
Само по себе это, конечно же, ещё не означает, что этот домен до сих пор принадлежит этому же человеку. Хотя это тоже не исключено. Но стоит помнить что он мог этот домен, например, продать. Не смотря на это, из истории записей, мы получили вполне конкретное направление, по которому можно будет поработать.
На этом же ресурсе мы можем сделать обратный поиск доменов по имени, названию компании, электронной почте и по ключевым словам. Это может быть полезно если нужно найти принадлежащие кому-то домены.
Ещё один ресурс для обратного поиска: https://whoisology.com. Умеет искать по домену, электронной почте и ключевым словам.
Веб-архив
При изучении какого-то сайта, особенно если это большое расследование, помимо того что нужно сохранять себе найденную информацию, есть смысл также сохранять страницы сайта на которых эта информация была найдена. Это нужно чтобы можно было позже вернуться к этой странице и повторно изучить. А также если сайт будет удалён или изменён, у тебя останутся пруфы, что информация была найдена именно там. Каким способом это делать не особо принципиально, делай так как удобнее тебе. Я, например, сохраняю страницы в pdf. Кто-то добавляет их в веб-архив. Кому-то больше нравится выкачивать весь сайт целиком. А кто-то просто делает скриншоты.
Также важно помнить, что информация на сайте, с течением времени, могла быть либо удалена, либо изменена. И бывает так, что это именно та информация которая нам нужна. В этой ситуации нам поможет веб-архив.
https://archive.org — вводим адрес нужного нам сайта и видим календарь в котором отмечены даты за которые есть сохранённые снимки. Сверху видим временную шкалу с разбивкой по годам. Тут важно помнить, что это не даты когда на сайт вносились изменения. Archive.org не следит за сайтами в режиме онлайн. Это даты когда сайт сканировался и делался его снимок.

Если нужно узнать когда и какие изменения вносились, то переходим в раздел «Changes«. Здесь синими и зелёными квадратиками отмечены даты когда сделанный снимок отличался от предыдущего. Мы можем выбрать нужные нам даты и нажать «Compare«. После этого откроется окно разделённое на две части. В них будут показаны снимки нашего сайта за выбранные даты. Обнаруженные изменения в одном окне будут отмечены жёлтым, в другом синим. Таким способом можно быстро находить что было изменено на сайте.
В этом примере мы смотрели снимки главной страницы сайта, но в реальной ситуации нам, почти всегда, нужно будет ознакомится и с другими страницами. Можно конечно просто копировать ссылку и искать по ней. Это удобно если мы точно понимаем какая именно страница нам нужна. А если мы этого не знаем, то у нас есть вкладки «Site Map» и «URLs».
На вкладке «Site Map» мы увидим карту сайта в виде диаграммы. В центре будет главная страница, а вокруг будут страницы, снимки которых есть в архиве. Когда мы наводим курсор на какой-то элемент, нам показывают ссылку на соответствующую страницу. Также мы можем выбрать за какой год нас интересует информация.
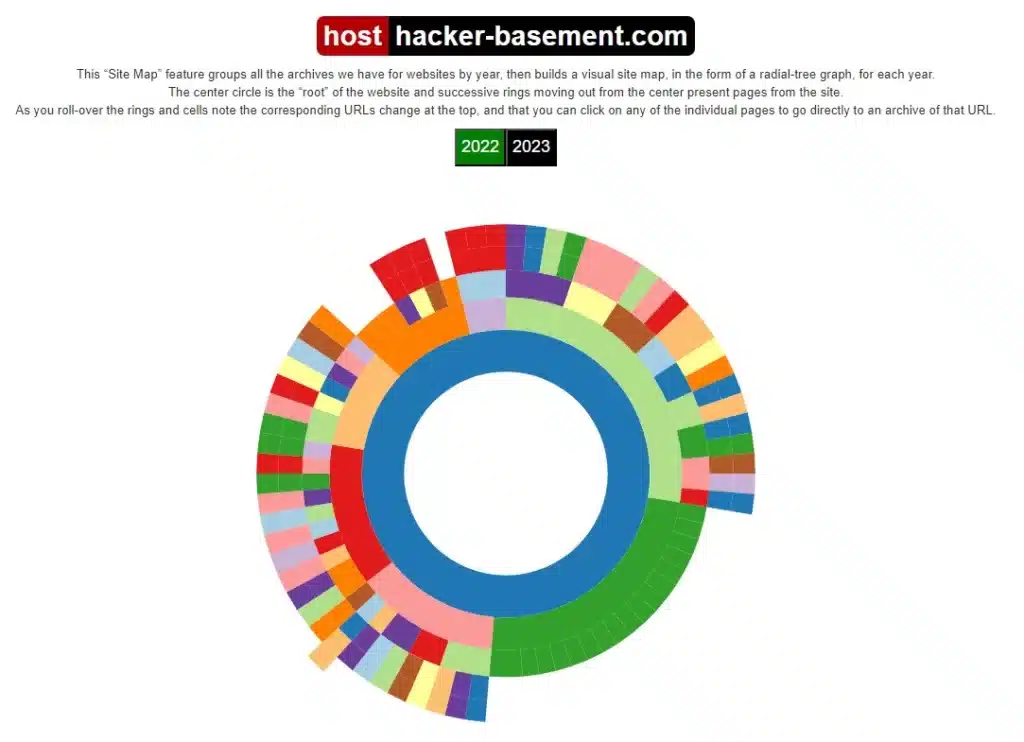
На вкладке «URLs» мы увидим список страниц сайта для которых есть снимок. В том числе мы видим сколько всего было снимков, сколько из них уникальных, а сколько одинаковых.
https://archive.is — ещё один веб-архив. Проще чем предыдущий, без каких-либо замороченных функций. Просто сохраняет снимки страниц и делает скриншот страницы. Работает довольно быстро. И, на мой взгляд, он удобен именно как инструмент сохранения нужных страниц, а не инструмент изучения сайта.
Кэш сайта
Также не стоит забывать про такую штуку как кэш гугла. Смысл его в том, что бот гугла, когда посещает страницу, сохраняет её в кэше в том виде в котором она была на момент посещения. Это может быть полезно когда нужный нам сайт не доступен на данный момент.
Есть несколько способов посмотреть данные из кеша. Можно прямо из поисковика. Находим нужную нам страницу. Возле адреса жмём на три точки и, в открывшемся окне, нажимаем «Сохранённая копия».

Ещё один способ, это сходить на http://www.cachedpages.com. И там ввести нужную ссылку. Там же можно перейти в веб-архив.
Мониторинг изменений
Следующая ситуация может случиться, если ты изучаешь чью-то деятельность. Тебе может понадобится мониторить изменения сайта в реальном времени.
https://distill.io — это расширение браузера. Либо можно установить десктопное приложение. На мой взгляд это наиболее удобный сервис. В бесплатной версии можно отслеживать 25 ссылок. Можно настроить, чтобы он обращал внимание только на какие-то конкретные изменения. Также он ведёт журнал изменений т.е. запоминает когда и какие изменения вносились на страницу, что тоже очень важно.
https://www.followthatpage.com — то же самое, но в чуть более упрощённом варианте. Добавляем ссылку на нужную нам страницу, после чего указываем нашу электронную почту. После добавления можно будет настроить фильтры. Фильтровать можно по строкам или по блокам. Если фильтруем по строкам, то нужно указать ключевое слово и все строки содержащие это слово будут игнорироваться. Если фильтруем по блокам, то нужно выбрать начало и конец блока, всё что между ними будет игнорироваться. Уведомления о изменениях будут приходить на указанную нами почту, в письме будет указанно что именно изменилось на отслеживаемой странице. В бесплатной версии может следить за 20 страницами.
Если нужно следить за большим количеством ресурсов, то тогда есть платный вариант: https://changedetection.io. Удобно, целая куча всяких возможностей и настроек, но за деньги. Есть ещё вариант, в предыдущих сервисах создать кучу аккаунтов и следить за большим количеством сайтов. Но это, скажем так, будет не самая комфортная история.
Рекламные идентификаторы
Многие сайты используют у себя сервисы Google для аналитики и монетизации. Естественно эти сервисы каждому аккаунту присваивают уникальный идентификатор, который потом используется на всех сайтах имеющих отношение к этому аккаунту. Соответственно мы можем, используя эти идентификаторы, находит аффилированные сайты. Но при этом нужно понимать некоторые нюансы.
Google Analytics — это сервис для статистики и отслеживания активности пользователя на сайте. Там ещё куча всего, но сейчас это не особо важно. Важно понимать, что аккаунт просто привязан к почте, а значит их можно насоздавать бесконечно много. Ну и какой-то персональной привязки к человеку, кроме адреса почты, он иметь не будет.
AdSense — это сервис для монетизации. Реклама, которую ты видишь на сайте, добавляется через AdSense. И так как это бабловая история, то и процедура регистрации посложнее и есть ограничение: один аккаунт на одного человека. Но самая главная заморочка там, это физическое письмо которое приходит на почтовый адрес и идти оно может около месяца, а то и больше. В этом письме будет код, и пока ты его не введешь, бабло ты получать не будешь.
Понятное дело, что это тоже не панацея и, при должном желании, можно нарегать аккаунтов на дропов. Но замороченная процедура регистрации увеличивает вероятность того, что на нескольких сайтах будет один и тот же AdSense. Соответственно, при изучении сайта, в приоритете стоит обращать внимание именно на идентификатор AdSense.
Идентификатор Google Analytics имеет формат: UA-набор цифр.
Идентификатор AdSense имеет формат: ca-pub-набор цифр или pub-набор цифр.
Есть несколько способов как их находить. Можно вручную. Открываем нужную страницу, жмём Ctrl+U. Откроется вкладка с исходным кодом страницы. Здесь жмём Ctrl+F, и в поиске пишем UA- или pub-

Если руками лень или не хочется, то можно использовать сервисы которые умеют их извлекать. Там же можем сразу поискать сайты на которых используются такие же идентификаторы. Оптимальный вариант это https://analyzeid.com. Просто вводим нужный нам адрес сайта, и он сам найдёт идентификаторы и все сайты которые их используют.
Ищет он очень не плохо, но чтобы перестраховаться можно проверить и на других подобных ресурсах:
https://dnslytics.com — в разделе Reverse Tools выбираем Reverse Adsense или Reverse Analytics и ищем по нужному нам идентификатору.
https://spyonweb.com — в поле поиска вводим домен или идентификатор, смотрим результаты. Тоже справляется очень достойно.
Метаданные
Тема с метаданными стара как мир, но не смотря на это, вполне может давать результаты. Если говорить про метаданные медиафайлов, то, проверить, хотя бы выборочно, конечно можно, но шансы получить результат откровенно не большие. Тут нужно смотреть по ситуации, если мы видим какие-то стоковые картинки или изображения явно взятые из поиска, то можно и не заморачиваться. Тем более, что популярные CMS, тот же WordPress например, вполне умеют чистить метаданные загружаемых медиафайлов. Поэтому, в случае с картинками, если они хоть сколько-нибудь уникальны, то гораздо актуальнее через поиск по изображениям поискать где они ещё встречаются.
Проверить метаданные изображения можно тут: https://www.imgonline.com.ua/exif.php
Гораздо более актуальна тема метаданных у документов. Их гораздо реже чистят принудительно. Другой вопрос в том, что документы далеко не на всех сайтах присутствуют, но проверять стоит всегда. И если они всё-таки есть, то кроме метаданных нужно обязательно смотреть содержимое, там вполне могут быть какие-то нужные данные.
Искать документы на сайте можно используя Google и его дорки filetype: и site:, например:
filetype:pdf site:hacker-basement.com
Если документов больше чем чуть-чуть, то руками качать и проверять это не самая оптимальная затея. Особенно учитывая, что кроме pdf, нам нужно ещё проверить текстовые документы, таблицы и презентации. В такой ситуации стоит использовать утилиту Metagoofil. Она скачает все нужные нам файлы, извлечёт метаданные и покажет их в удобном виде. Подробную инструкцию как использовать Metagoofil я уже писал, потому повторятся не вижу смысла: Метаданные. Metagoofil. Что и как можно найти на сайте?
Сайт и технологии
Изучение технологий сайта, или, другими, словами того что у него под капотом, с точки зрения OSINT, это история из серии «я тебя по IP вычислю». Т.е. шанс конечно есть, но очень не большой. Я именно по этому этот раздел поместил в конец статьи. Но, справедливости ради, стоит отметить что иногда, все-таки из этого всего можно получить полезную информацию, которая, в комплексе с другими данными, может дать результат. Поэтому давай разберёмся с некоторыми моментами.
VirusTotal
Вообще, первое что тебе нужно сделать, перед изучением сайта, ещё до того как ты на него зайдёшь, это проверить его на https://www.virustotal.com. Во-первых убедится, что с сайтом всё хорошо и ты не зацепишь оттуда что-нибудь не хорошее. Во-вторых получить первичную информацию.
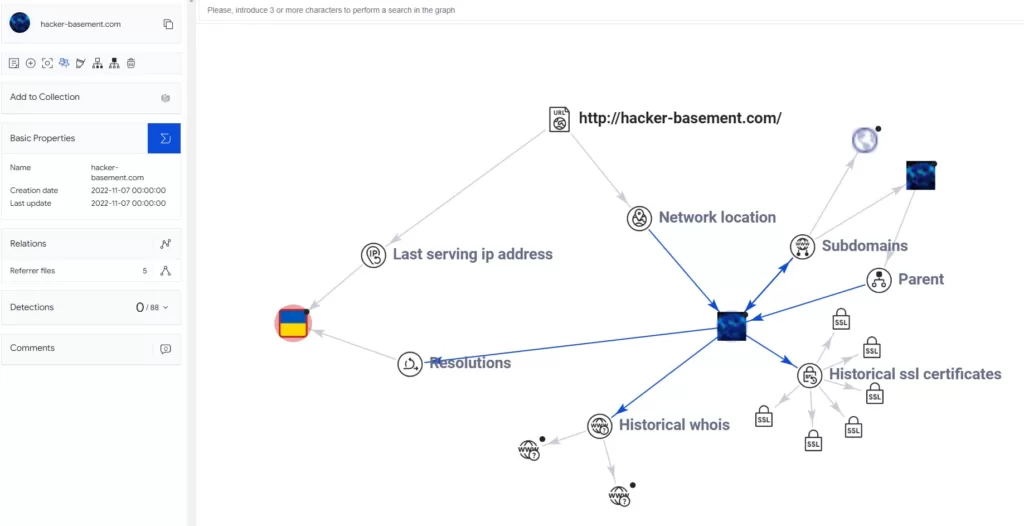
В разделе DETAILS мы можем посмотреть IP сайта (и оттуда же его проверить), а также увидеть заголовки, описание и трекеры которые на сайте используются, в том числе их идентификаторы. В разделе LINKS мы увидим все исходящие ссылки которые есть на странице. Также полезным может быть раздел Graph. Здесь можно в графическом виде создать схему связей сайта, его IP, поддоменов и т.д., в том числе можно посмотреть историю WHOIS и SSL сертификатов.
SSL сертификати
Ну и раз я упомянул SSL сертификат, то давай пару слов об этом. Это такая штука которая нужна чтобы шифровать данные при передаче т.е. использовать протокол HTTPS, это элемент повышения доверия между клиентом и сервером. Этот сертификат выдаётся центрами сертификации. Очень часто ты будешь видеть сертификат выданный Let’s Encrypt. Потому что это бесплатно и любой адекватный хостинг умеет подключать этот сертификат на автомате. Для его получения не требуется какая-либо персонализированная информация. А значит для нас он бесполезен.
Но иногда, в основном крупные организации, покупают платный сертификат. И в этом случае мы можем получить из него полезную информацию. Там будет указано название организации, которая купила сертификат и электронная почта. А, анализируя историю этих сертификатов, можно собирать данные об организациях имеющих отношение к изучаемому сайту.
https://crt.sh — вводим нужный нам домен и смотрим информацию о SSL сертификатах.
Технологии
Вернёмся к технологиям. Есть огромное количество ресурсов позволяющих получить данные о сайте, но лично мне нравится и удобнее https://web-check.as93.net
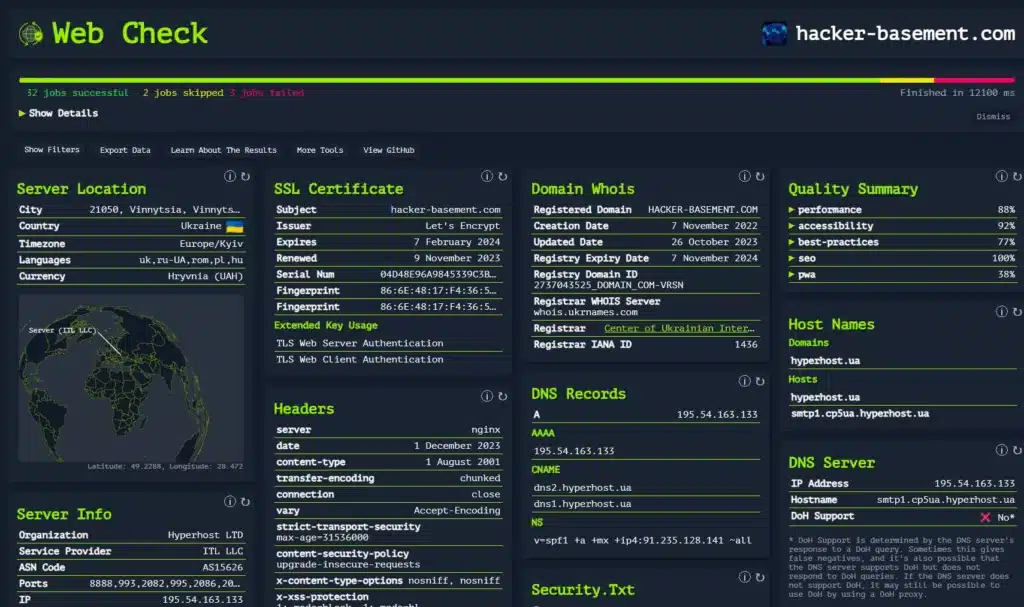
Информации там будет много, но далеко не вся она может быть нам полезна. Давай посмотрим что мы можем использовать.
Локация сервера. Т.е. в какой стране хостится сайт, иногда будет информация о городе. Это конечно же, далеко не всегда означает, что владелец сайта тоже находится там. Чаще всего это локация хостинга. Но всё же некоторую привязку к местности это даёт, потому обращаем внимание. Здесь ещё стоит посмотреть на NS записи в разделе DNS Records. Если там ты видишь Cloudflare, то локацию тебе покажет из США. Но это локация Cloudflare, не сервера сайта.
DNS записи. Здесь мы видим IP адрес и можем стразу сходить на https://dnslytics.com и через обратный поиск посмотреть другие сайты на этом IP. Хотя тут тоже есть нюансы. Во-первых обращаем внимание на раздел Host Names. Если там мы видим какой-то хостинг, то эта затея не имеет никакого смысла т.к. сайтов на этом адресе будет целая куча и найти связанные, даже если они там есть, по одному только IP не получится. Эта манипуляция будет иметь смысл если на одном IP адресе находится какое-то небольшое количество сайтов.
В разделе Pages мы увидим sitemap сайта. Из полезного оттуда мы можем узнать хронологию изменения страниц и добавления картинок. Не факт что это очень полезная информация, но в комплексе с какими-нибудь ещё данными может пригодится.
В разделе Linked Pages мы можем увидеть внутренние и внешние ссылки, которые есть на странице.
Ещё стоит обратить внимание на раздел Redirect Chain. Если сайт хочет нас куда-то перенаправить, возможно это какие-то связанные между собой ресурсы.
Итог
Как видишь процесс поиска владельца сайта может оказаться довольно замороченной задачей. Но при этом абсолютно реальной. Основные направления куда смотреть я тебе показал. А от тебя требуется только внимательность и немного аналитического мышления, в плане комбинирования информации между собой и поиска правильных направлений. Т.е. когда ты нашёл какую-то зацепку, её нужно правильно использовать и дополнить, превратив в цепочку ведущую к результату. Ну и очень важно выписывать всю найденную информацию. Не пытайся держить её в голове, ты по-любому что-то пропустишь или забудешь.
Твой Pulse.